We Tested How Googlebot Crawls Javascript And Here’s What We Learned
Think Google can't handle JavaScript? Think again. Contributor Adam Audette shares the results of a series of tests conducted by his colleagues at Merkle | RKG to examine how different JavaScript functions would be crawled and indexed by Google.

TL;DR
1. We ran a series of tests that verified Google is able to execute and index JavaScript with a multitude of implementations. We also confirmed Google is able to render the entire page and read the DOM, thereby indexing dynamically generated content.
2. SEO signals in the DOM (page titles, meta descriptions, canonical tags, meta robots tags, etc.) are respected. Content dynamically inserted in the DOM is also crawlable and indexable. Furthermore, in certain cases, the DOM signals may even take precedence over contradictory statements in HTML source code. This will need more work, but was the case for several of our tests.
Introduction: Google Executing Javascript & Reading The DOM
As early as 2008, Google was successfully crawling JavaScript, but probably in a limited fashion.
Today, it’s clear that Google has not only evolved what types of JavaScript they crawl and index, but they’ve made significant strides in rendering complete web pages (especially in the last 12-18 months).
At Merkle, our SEO technical team wanted to better understand what types of JavaScript events Googlebot could crawl and index. We found some eye-opening results and verified that Google is not only executing various types of JavaScript events, they are also indexing dynamically generated content. How? Google is reading the DOM.
What Is The DOM?
Far too few SEOs have an understanding of the Document Object Model, or DOM.

What happens when a browser requests a web page, and how the DOM is involved.
As used in web browsers, the DOM is essentially an application programming interface, or API, for markup and structured data such as HTML and XML. It’s the interface that allows web browsers to assemble structured documents.
The DOM also defines how that structure is accessed and manipulated. While the DOM is a language-agnostic API (not tied to a specific programming language or library), it is most commonly used in web applications for JavaScript and dynamic content.
The DOM represents the interface, or “bridge,” that connects web pages and programming languages. The HTML is parsed, JavaScript is executed, and the result is the DOM. The content of a web page is not (just) source code, it’s the DOM. This makes it pretty important.
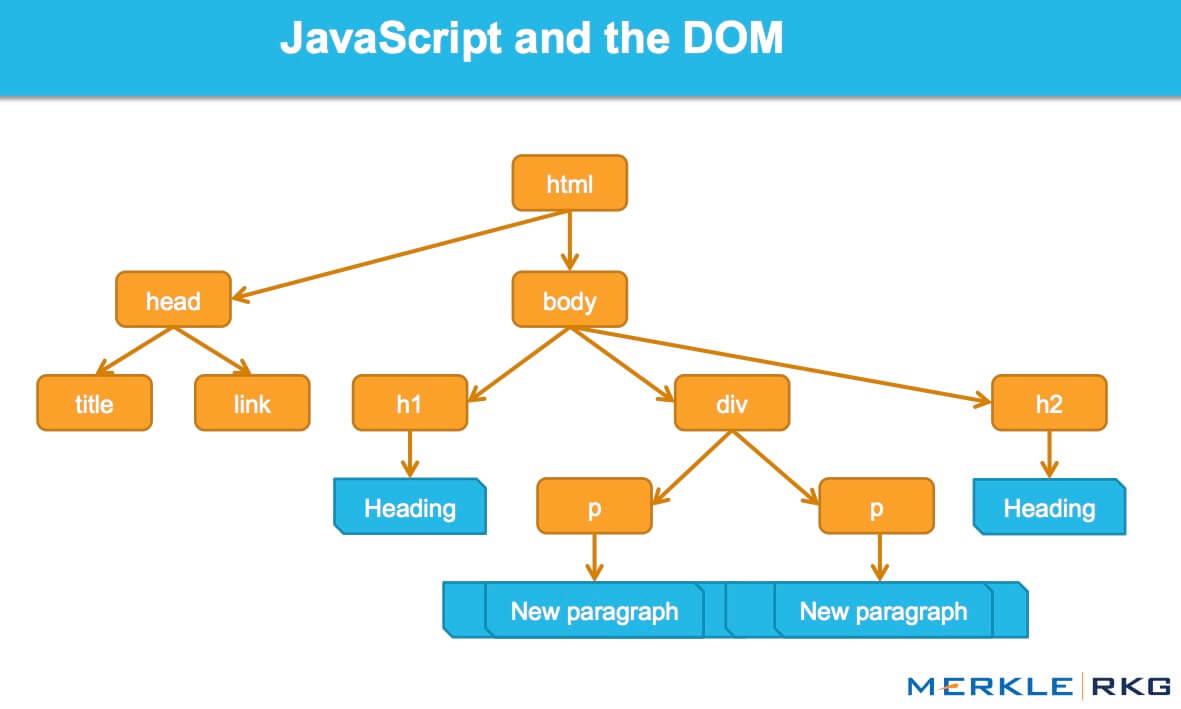
How JavaScript works with the DOM interface.
We were thrilled to discover Google’s ability to read the DOM and interpret signals and content that were dynamically inserted, such as title tags, page text, heading tags and meta annotations like rel=canonical. Read on for the full details.
The Series Of Tests And Results
We created a series of tests to examine how different JavaScript functions would be crawled and indexed, isolating the behavior to Googlebot. Controls were created to make sure activity to the URLs would be understood in isolation. Below, let’s break down a few of the more interesting test results in detail. They are divided into five categories:
- JavaScript Redirects
- JavaScript Links
- Dynamically Inserted Content
- Dynamically Inserted Meta Data and Page Elements
- An Important Example with rel=“nofollow”
One example of a page used for testing Googlebot’s abilities to understand JavaScript.
1. JavaScript Redirects
We first tested common JavaScript redirects, varying how the URL was represented in different ways. The method we chose was the window.location function. Two tests were performed: Test A included the absolute URL attributed in the window.location function. Test B used a relative URL.
Result: The redirects were quickly followed by Google. From an indexing standpoint, they were interpreted as 301s — the end-state URLs replaced the redirected URLs in Google’s index.
In a subsequent test, we utilized an authoritative page and implemented a JavaScript redirect to a new page on the site with exactly the same content. The original URL ranked on the first page of Google for popular queries.
Result: As expected, the redirect was followed by Google and the original page dropped from the index. The new URL was indexed and immediately ranked in the same position for the same queries. This surprised us, and seems to indicate that JavaScript redirects can (at times) behave exactly like permanent 301 redirects from a ranking standpoint.
The next time your client wants to implement JavaScript redirects for their site move, your answer might not need to be, “please don’t.” It appears there is a transfer of ranking signals in this relationship. Supporting this finding is a quote from Google’s guidelines:
Using JavaScript to redirect users can be a legitimate practice. For example, if you redirect users to an internal page once they’re logged in, you can use JavaScript to do so. When examining JavaScript or other redirect methods to ensure your site adheres to our guidelines, consider the intent. Keep in mind that 301 redirects are best when moving your site, but you could use a JavaScript redirect for this purpose if you don’t have access to your website’s server.
2. JavaScript Links
We tested several different types of JavaScript links, coded various ways.
We tested dropdown menu links. Historically search engines haven’t been able to follow these types of links consistently. Our test sought to identify if the onchange event handler would be followed. Importantly, this is a specific type of execution point: we are asking for an interaction to change something, not a forced action like the JavaScript redirects above.
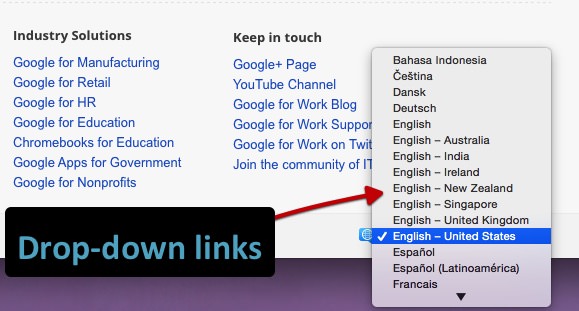
An example drop down language selector on a Google for Work page.
Result: The links were fully crawled and followed.
We also tested standard JavaScript links. These are the most common types of JavaScript links that SEOs have traditionally recommended be changed to plain text. These tests included JavaScript links coded with:
- Functions outside of the href Attribute-Value Pair (AVP) but within the a tag (“onClick”)
- Functions inside the href AVP (“javascript:window.location“)
- Functions outside of the a but called within the href AVP (“javascript:openlink()”)
- etc.
Result: The links were fully crawled and followed.
Our next test was to examine further event handlers like the onchange test above. Specifically, we were looking at the idea of mouse movements as the event handler and then hiding the URL with variables that only get executed when the event handler (in this case onmousedown and onmouseout) is fired.
Result: The links were crawled and followed.
Concatenated links: we knew Google can execute JavaScript, but wanted to confirm they were reading the variables within the code. In this test, we concatenated a string of characters that created a URL once it was constructed.
Result: The link was crawled and followed.
3. Dynamically Inserted Content
This is clearly an important one: dynamically inserted text, images, links and navigation. Quality text content is critical to a search engine’s understanding of the topic and content of a page. In this era of dynamic websites it’s even more important SEOs get on top of this.
These tests were designed to check for dynamically inserted text in two different situations.
1. Test the search engine’s ability to account for dynamically inserted text when the text is within the HTML source of the page.
2. Test the search engine’s ability to account for dynamically inserted text when the text is outside the HTML source of the page (in an external JavaScript file).
Result: In both cases, the text was crawled and indexed, and the page ranked for the content. Winning!
For more on this, we tested a client’s global navigation that is coded in JavaScript, with all links inserted with a document.writeIn function, and confirmed they were fully crawled and followed. It should be noted that this type of functionality by Google explains how sites built using the AngularJS framework and the HTML5 History API (pushState) can be rendered and indexed by Google, ranking as well as conventional static HTML pages. That’s why it is important to not block Googlebot from accessing external files and JavaScript assets, and also likely why Google is moving away from its supporting Ajax for SEO guidelines. Who needs HTML snapshots when you can simply render the entire page?
Our tests found the same result regardless of content type. For example, images were crawled and indexed when loaded in the DOM. We even created a test whereby we dynamically generated data-vocabulary.org structured data markup for breadcrumbs and inserted it in the DOM. Result? Successful breadcrumbs rich snippets in Google’s SERP.
Of note, Google now recommends JSON-LD markup for some structured data. More to come I’m sure.
4. Dynamically Inserted Meta Data & Page Elements
We dynamically inserted in the DOM various tags that are critical for SEO:
- Title elements
- Meta descriptions
- Meta robots
- Canonical tags
Result: In all cases the tags were crawled respected, behaving exactly as HTML elements in source code should.
An interesting follow-up test will help us understand order of precedence. When conflicting signals exist, which one wins? What happens if there’s a noindex,nofollow in source code and a noindex,follow in the DOM? How does the HTTP x-robots response header behave as another variable in this arrangement? This will be a part of future comprehensive testing. However, our tests showed that Google can disregard the tag in source code in favor of the DOM.
5. An Important Example with rel=”nofollow”
One example proved instructive. We wanted to test how Google would react to link-level nofollow attributes placed in source code and placed in the DOM. We also created a control without nofollow applied at all.

Our nofollow test isolating source code vs DOM generated annotations.
The nofollow in source code worked as expected (the link wasn’t followed). The nofollow in the DOM did not work (the link was followed, and the page indexed). Why? Because the modification of the a href element in the DOM happened too late: Google already crawled the link and queued the URL before it executed the JavaScript function that adds the rel=“nofollow” tag. However, if the entire a href element with nofollow is inserted in the DOM, the nofollow is seen at the same time as the link (and its URL) and is therefore respected.
Ramifications
Historically, SEO recommendations have centered around having ‘plain text’ content whenever possible. Dynamically generated content, AJAX, and JavaScript links have been a detriment to SEO for the major search engines. Clearly, that is no longer the case for Google. Javascript links work in a similar manner to plain HTML links (at face value, we do not know what’s happening behind the scenes in the algorithms).
- Javascript redirects are treated in a similar manner as 301 redirects.
- Dynamically inserted content, and even meta signals such as rel canonical annotations, are treated in an equivalent manner whether in the HTML source, or fired after the initial HTML is parsed with JavaScript in the DOM.
- Google appears to fully render the page and sees the DOM and not just the source code anymore. Incredible! (Remember to allow Googlebot access to those external files and JavaScript assets.)
Google has innovated at a frightening pace and left the other search engines in the dust. We hope to see the same type of innovation from other engines if they are to stay competitive and relevant in the new era of web development, which only means more HTML5, more JavaScript, and more dynamic websites.
SEOs, too, who haven’t kept pace with the underlying concepts here and abilities of Google would do well to study up and evolve their consulting to reflect current technologies. If you don’t take the DOM into consideration, you may be missing half of the picture.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author